JPA란?
- JPA는 Java Persistence API 이다.
- JPA는 ORM 기술이다.
- JPA는 반복적인 CRUD 작업을 생략하게 해준다.
- JPA는 영속성 컨텍스트를 가지고 있다.
- JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다. (DB는 객체저장 불가능)
- JPA는 OOP의 관점에서 모델링을 할 수 있게 해준다. (상속, 콤포지션, 연관관계)
- 방언 처리가 용이하여 Migration하기 좋음. 유지보수에도 좋음.
- JPA는 쉽지만 어렵다.
JPA는 Java Persistence API 이다.
⇒ persistence: 영속성
컴퓨터의 ram에 있는 데이터는 휘발성이다.
이 데이터를 날아가지 못하게 하기 위해 하드디스크에 영구적으로 저장을 한다.
영속성 : 데이터를 생성한 프로그램이 종료되더라도 데이터는 사라지지 않는 것.
Java Persistence⇒
자바에 있는 데이터를 dbms에(자바는 컴퓨터 파일시스템에 저장하는게 아니므로) 저장함으로서 영구히 저장하는 환경.
그럼 api는?

application ⇒프로그램
programming⇒ 저 프로그램을 만드는 방법
interface⇒ 이 인터페이스를 활용해 프로그래밍을 한다
그럼 이 프로그램을 만들기 위해 필요한 인터페이스가 뭘지
프로토콜 | 인터페이스
⇒ 둘 다 약속인것은 같으나…

장보고와 홍길동의 약속이지만,
이 프로그램은 장보고가 배포하는 것 이므로 홍길동과 협의 할 필요가 없음!
장보고가 만든 약속을 홍길동이 지키는 것.
즉, 인터페이스는 상하관계가 존재하는 약속임.
프로토콜은 서로 동등한 관계에서 약속하는 것.
즉
JPA는
Java Persistence api
자바에 있는 데이터를 영구히 저장하는 인터페이스.
JPA는 ORM 기술이다.
object relational mapping


밀어넣는 과정을 DML (DELETE UPDATE INSERT), 가져올 땐 SELECT
이 때 자바의 데이터타입과 데이터베이스의 타입은 다름.
⇒ 그러므로 class로 모델링을 하게됨
원래라면 데이터베이스에 먼저 테이블을 만들고 모델링할 클래스를 만들어야 하지만
이건 table relational mapping이 아닌, object relational mapping.
class에 있는 것으로 데이터 베이스 테이블을 만들 수 있음.
이때 필요한게 바로 jpa의 인터페이스!
JPA는 반복적인 CRUD 작업을 생략하게 해준다.
c: create
r:select
u:update
d:delete
자바 ⇒ db로 커넥션 요청하면, db는 자바의 신분을 확인 후 세션을 오픈함.
그럼 둘은 연결이되고 자바는 connection을 갖게됨
connection을 가지면 자바는 쿼리를 db에 전송할 수 있음. 그럼 db는 쿼리에 맞는 데이터를 생성해 자바에 응답해줌.
데이터 타입이 서로 다르므로 자바는 응답받은 데이터를 자바 object로 바꿔야함
→ 이 모든 과정이 너무나 귀찮음
⇒jpa의 함수 하나로 이 과정을 처리할 수 있다.
JPA는 영속성 컨텍스트를 가지고 있다.
영속성 : 데이터를 영구적으로 저장
context의 개념 굉장히 모호. 대상에 대한 모든 정보
영속성 컨텍스트는 자바가 데이터베이스에 저장해야하는 모든 정보를 다 들고 있음.
자바에서 내용을 바꾸면 영속성컨텍스트에 있던 과일 데이터도 동기화되서 자동으로 바뀌고,
DB에 정보 UPDATE도 영속성 컨텍스트가 해줌으로써 데이터 동기화가 된다.
그리고 자바 데이터와 DB 데이터의 타입 컨버팅도 해줌.
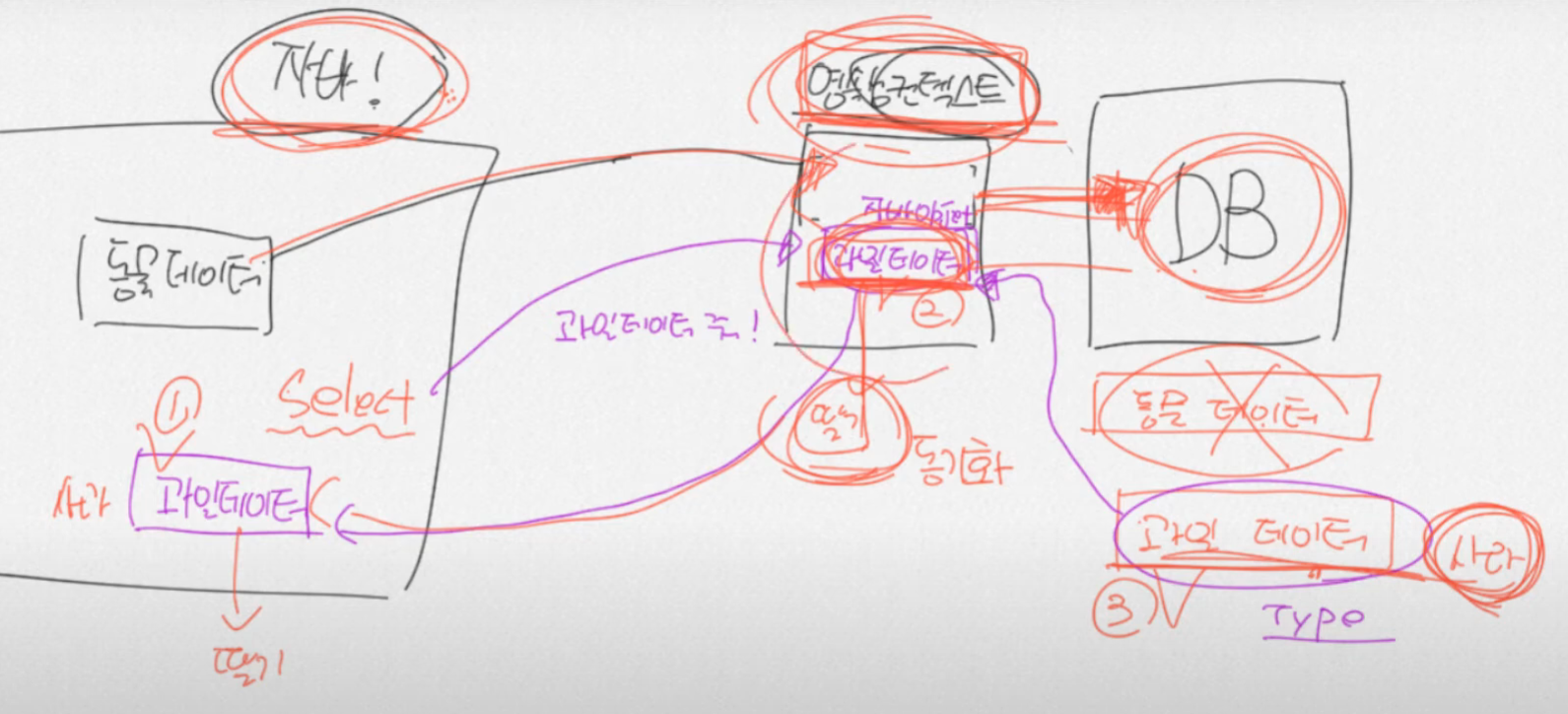
JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다. (DB는 객체저장 불가능)

DB의 이런데이터가 자바에서 클래스가 된다면?

그럼 여기서 TEAM ID = 1 을 보고 일반 사용자가 저게 무엇인지 바로 알수 있는가? 없다

그걸 해결하기 위해서 JOIN을 쓰지만…
⇒ 이건 oop가아니라 db에 맞춰 프로그래밍 하는거
자바에선 object가 있는데 이렇게 할 이유 없지않나? 자바에게 주도권을 줘서 oop를

근데 이러면 db에선 int인데, 자바의 object를, 즉 객체를 어떻게 집어넣을 수 있을까? 모순된다.
이걸 db에 집어넣을때 자동으로 team id를 fk로 넣어서 모순을 해결해 주는 것
그게 바로 ORM이다.
JPA는 OOP의 관점에서 모델링을 할 수 있게 해준다. (상속, 콤포지션, 연관관계)

car클래스와 엔진 클래스는 상속 관계가 아니다. 엔진이 car의 부모가 될 수 없기 때문에.
그래서 콤포지션이 있어야함(결합)
car클래스를 만들어 객체로 엔진을 사용하면 jpa가 자동으로 db에 테이블을 생성해줄것,
이제 모든 클래스에 날짜를 넣고 싶을때,

클래스마다 날짜를 추가하는 것은 비효율적,

entitydates란 클래스를 만들어서 date를 넣고, 각 클래스마다 이 클래스를 상속하게한다.


그럼 db에선 이런 테이블이 만들어짐(상속을 하게 되면 밑으로 필드가 더 생기는 거니까.)

방언(dialect) 처리가 용이하여 Migration하기 좋음. 유지보수에도 좋음.

jpa에 특정 객체만 적용되는 것이 아니라 추상화 객체가 있어서 내가 뭘 사용하든 상관없이 db에 연결된다.
내가 오라클을 쓰다가 사용기한 만료로 mysql로 바뀌어도 문제없이 유지보수가능
JPA는 쉽지만 어렵다.
처음에는 쉽지만 방대한 데이터가 들어오면 내부에 있는 쿼리관리가 어려움.
자료 출처 : 스프링부트 강좌 with JPA -메타코딩
'백 > spring boot' 카테고리의 다른 글
| 스프링부트 - mybatis 사용하기 (0) | 2023.07.12 |
|---|---|
| 스프링 부트 프로젝트 생성하기(gradle) (0) | 2023.07.12 |
| 스프링 부트 프로젝트 생성하기(Maven) (0) | 2023.07.12 |
| 스프링부트 3. 스프링 부트 동작원리 (0) | 2023.06.19 |
| 스프링부트 1. 기본개념정리 (0) | 2023.06.19 |