1. 스프링부트 동작원리
(1) 내장 톰켓을 가진다.
톰켓을 따로 설치할 필요 없이 바로 실행가능하다.
우선 톰켓에대한 개념 정리 다시필요.
소켓이 뭔지 알아야함.
소켓 : 운영체제가 가지고 있는 것.
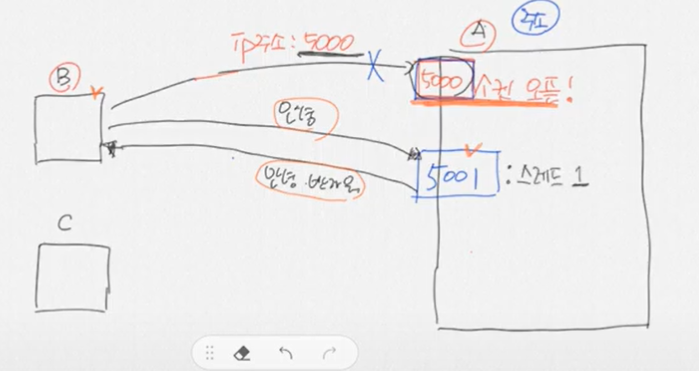
a가 5000번 포트를 열고 b가 ip주소 5000을 넣으면 서로 통신이 가능함.
그런데 이미 b가 a의 5000번 포트를 쓰고 있으면 c는 5000 번 포트로 연결할 방법이 없음
⇒5000번 포트는 연결용도로만 쓰고
새로운 포트를 랜덤 생성해서 그걸로 통신함
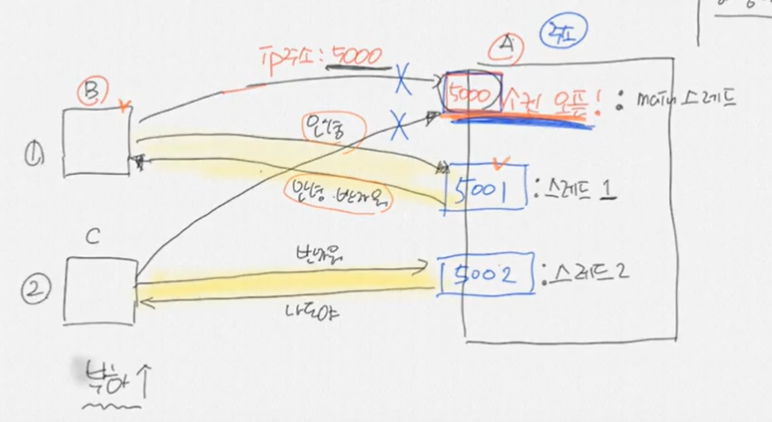
근데 이렇게 되면 다른 사용자의 요청을 받을 수 없음 cpu가 b와 5001번으로 소통하고 있기 때문에
⇒ 5001번을 만들때는 새로운 스레드를 만들어줌, 그리고 스레드가 만들어지면 원래 5000번은 끊김
소켓통신 : 시간을 쪼개서 동작.
- 장점: 연결이 계속 되어있음, 한번 연결되고 나면 지금 통신 대상이 누구인지 서버입장에서 알수있음
- 단점: 그래서 부하가 심함

http 통신 : stateless 방식 사용
문서를 전달하는 통신
한번 문서 전달 후 통신을 끊어버림(=stateless 방식)
- 장점: 부담이 적고 간편
- 단점: 새로 통신을 연결할때마다 얘가 누군지 전에 통신했던앤지 알수가 없음

http탄생 이야기
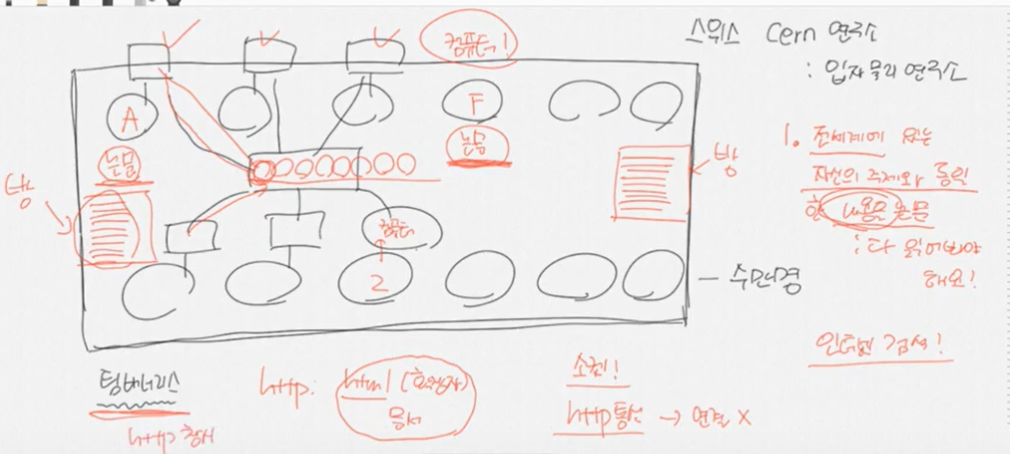
컴퓨터는 있지만, 인터넷검색 안될때여서 새로 논문을 내고 싶으면 직접 논문을 다 읽어봐야했음
팀 버너스리라는 사람이 모두의 컴퓨터를 하나의 서버에 연결,
자기가 쓴 논문을 서버컴퓨터에 옮기고, 필요하면 검색해서 다시 자기가 가져옴.
한번 문서 전달 후 연결은 끊김.
이게 http 통신 ⇒ 즉 http 통신의 목적은 필요한 사람에게 문서를 전달하는 것.
톰캣에 대해 다시 설명

http는 소켓을 시스템콜해서 만든 것, 즉 http의 기반은 소켓.
톰캣은 웹서버
웹서버를 설명하자면..?

내가 재밌는 동영상 3개를 들고 있다.
친구들이 내 동영상 3개를 보고싶음. 친구들이 나에게 이 동영상을 요청(request)
그럼 내(webserver)가 갑, 친구들이 을,
http통신은 항상 을이 갑에게 request함.
갑은 을 컴퓨터가서 데이터 가져올 필요 없으니
http 에서 갑은 을의 ip주소를 모른다. 갑은 을 컴퓨터에 가서 요청한 걸 을에게 주기만 하니까 알 필요가 없음.
즉 을이 요청하지 않으면 응답이 불가능!
이 자원들은 static 자원. (정적인 자원) 자원을 을에게 넘겨준 후 갑의 컴퓨터(서버)에서 변동사항이 있어도 업데이트 되지 않는다.
static 자원이 아닌 자원을 주기 위해선 을의 주소를 알고있어야 하고, 계속 연결이 지속되어있어야함
즉, 소켓을 써야함
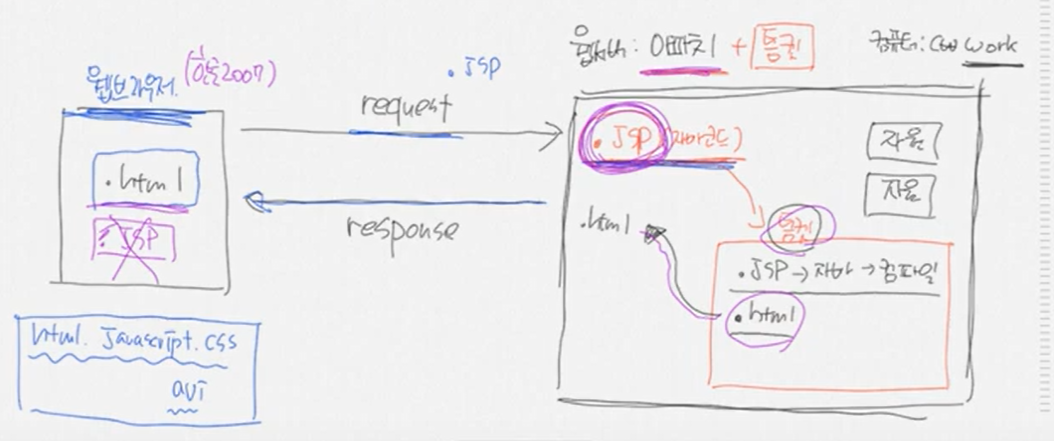
웹서버: 아파치 컴퓨터:c\work
어떤애가 request하면 그 자원을 response하면됨.
웹 브라우저가 .jsp(자바코드)를 요청하면 아파치는 이해하지 못함
웹브라우저도 .jsp파일을 요청하고 그대로 .jsp파일이 돌아온다면 읽어들이지 못함.
웹브라우저는 html javascript css 파일만 보여줄 수 있음.
톰캣은 jsp를 이해할 수 있기때문에 아파치에 톰캣을 붙여준다.
그럼 jsp파일 요청이 들어오면 아파치는 주도권을 톰캣에게 넘겨줌.
톰캣은 .jsp⇒ 자바⇒ 컴파일 하여 .html로 만들어줌
즉 톰캣이 하는일은 jsp를 .html파일로 컴파일해주는거라고 할수있음.
(2) 서블릿 컨테이너
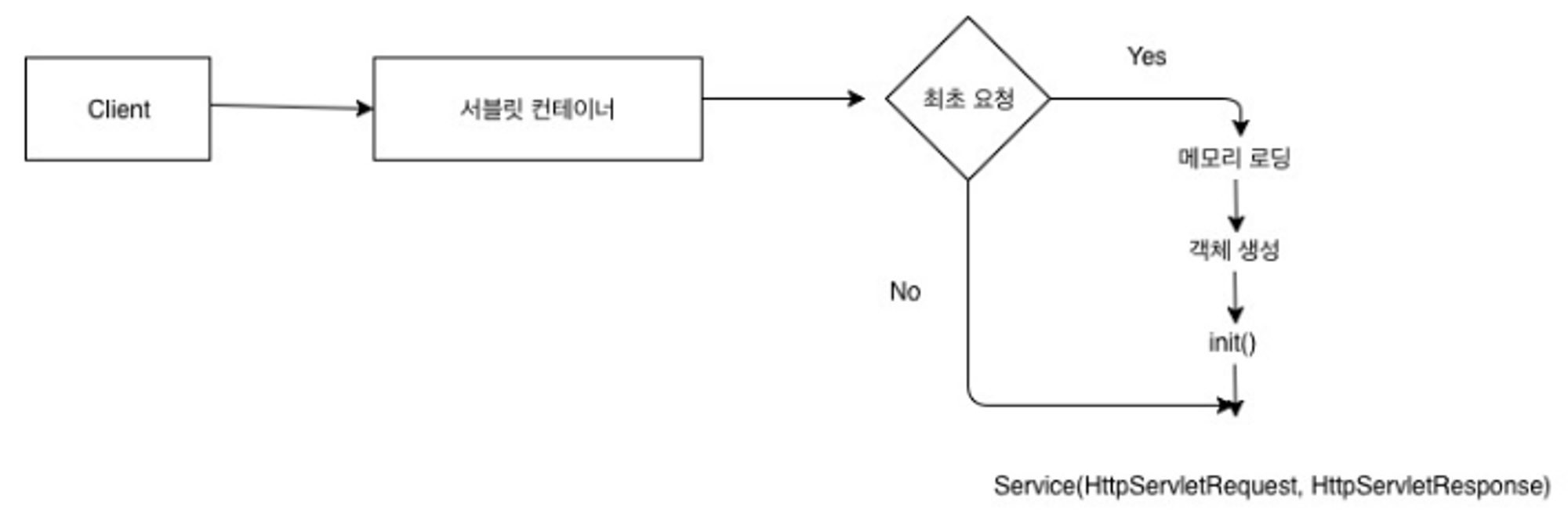
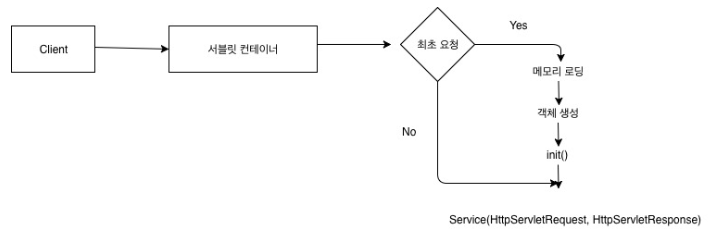
https://blog.kakaocdn.net/dn/OCwgQ/btqCtYeuOMu/ETtkL2p1e0IewF5IRq6WGK/img.png
출처 : https://minwan1.github.io/2018/11/21/2018-11-21-jsp-springboot-동작과정/
클라이언트가 요청하면 서블릿컨테이너(톰캣) 가 받고 최초요청이면 객체생성, 아니면 전에 만들었던 객체 그대로 사용
Service(HttpServletRequest, HttpServletResponse)에 대해서 이해해보자
.html, .css, .png 같은 정적 파일 요청받으면 톰캣말고 아파치가 일함
이런 파일 말고 자바파일 요청받으면 톰캣이 일을 시작함.
그런데 스프링은 정적파일 요청이 안됨.
왜냐?
url(location): 자원에 접근할때 필요한 요청방식 ⇒ 이거 스프링에서 사용 못함
uri(identifier): 식별자 접근
⇒특정한 파일 요청을 할 수 없다.
⇒요청시에는 무조건 자바를 거쳐야함.
⇒즉 톰캣이 무조건 발동
서블릿 : 자바코드로 웹을 할 수 있는것
서블릿 컨테이너 : 자바코드로 웹을 할 수 있게 만드는 것( 즉, 톰캣)
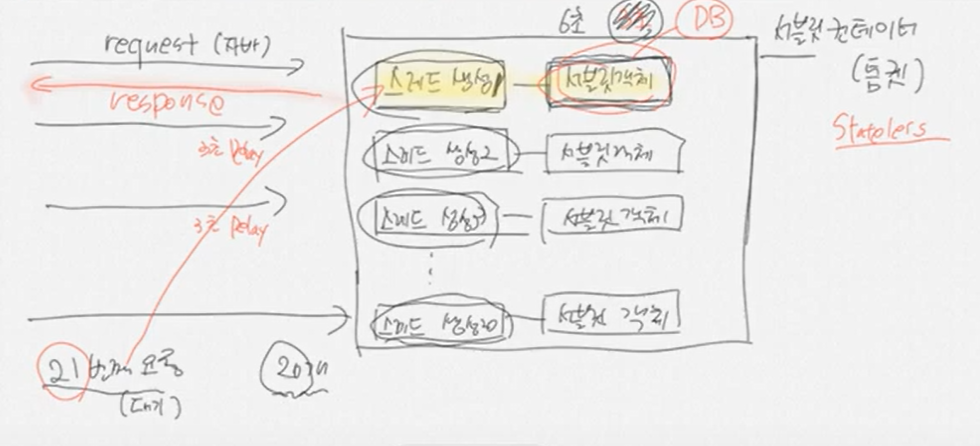
클라이언트가 request(자바) ⇒ 톰캣
스레드가 무한정 만들어지는 것 아님. 내가 정해놓은 갯수대로(서버 환경에 맞도록 만들어야함)
만약 스레드 제한을 20개로 만들어 놨는데, 하나씩 처리하는 시간이 있으므로 다음요청에 대해 딜레이가 있다고 하면, 20번째 요청까지 들어온 다음 21번째 요청은 대기상태가 된다.
1번째 응답을 마치고 나면 연결이 삭제되는게 아니라, 그 스레드를 21번째 요청에 재활용함
그럼 만들고 삭제하는 과정이 없어서 속도가 매우 빨라진다.
⇒
이렇게 리퀘스트와 리스폰스를 빋아 만들어진 객체가 HttpServletRequest, HttpServletResponse
Service(HttpServletRequest, HttpServletResponse)
⇒ 이건 스프링이 들고 있는게 아니라 톰캣이 들고있는거임
웹은 request 객체와 response객체의 여행인거임
(3) web.xml
- ServletContext의 초기 파라미터

관리자가 바뀔때마다 문지기가 하는일이 달라질 수는 있지만 , 문지기는 바뀌지 않는다.
문지기(web.xml)에게 초기 파라미터를 알려줌.
초기파라미터 : 암구호 = 왈라
초기파라미터는 한번 설정해두면 이 성 내부 어디에서든 통한다.
- Session의 유효시간 설정

session :
민증 등의 중요한 증거를 통해서 인증이 된 사람을 들어올 수 있게 하는것
세션 시간 설정을 3일로 해놓으면 인증받은 사람은 여기에 3일동안 머물 수 있다.
그 이상 머무르면 세셧에서 추방당하지만 문지기에게 가서 다시 인증을 하고 세션을 초기화하면 더 머무를 수 있음
몰래 들어온사람은 그렇게 할 수 없으므로 세션에서 추방됨

- Servlet/JSP에 대한 정의 +
- Servlet/JSP 매핑
- a가 들어오면 가고자하는 목적지를 문지기에게 말한다
- a: 저는 “다”로 갈거에요~~~
- 문지기 : (web.xml을 뒤져보고) “다” 는 서울 용산구에 있어용. ⇒(이게 servlet/jsp의 정의)
- 들어온 요청이 뭔지 보고 그거에 매핑된 주소를 알려주는 것⇒(이게 servlet/jsp 매핑)

- Mime Type 매핑
- 문지기 : 니가 들고 온 데이터의 타입이 뭐야?
- b: 아무것도 안들고온 애 ⇒ 아무것도 안들고온거면 이 성에 뭘 가지러온 거 ⇒ 즉 get방식⇒ select
- a: 쌀을 들고온애 ⇒ a: (mime type) 쌀이에용 ⇒ 문지기(web.xml)이 a를 쌀 창고에 보내줌
- 그럼 a가 들고온 쌀을 검수해서 쌀 창고에 저장함.
- 근데 만약 a가 쌀을 들고와놓고 물이라고 거짓말을 한다?(=mime type이 실제 데이터와 틀리다)
- ⇒ 컴퓨터는 그 거짓말을 식별할수 있는 능력 x , 물창고에 보내서 a가 들고온 쌀에다가 물 검사를 하므로 타입 미스매치 에러가 뜬다.
- Welcome File list
- 문지기: 너누구야 어디로갈거야 뭐들고왓어
- a : 그냥왓는데요(=주소창에 매핑할 값이 없음)
- 문지기 : 광장으로 가라,,(보통 index로 설정함)
- Error Pages 처리
- a :전 “파”로 갈거에요
- 문지기: (파..? 파가뭐지?우리 성은 가나다라밖에없는데..,?? error)
- 문지기: 너누구야 어디로갈거야 뭐들고왓어
그러므로 관리자가 web.xml에 알려줘야함
아무것도 안들고온애는 광장(index)으로 가지만, 들고왓는데 그게 우리 성에 없는 애면 에러 페이지를 보여줘라. 라고 지정해주는게 바로 error pages처리
- 리스너/필터 설정
- 필터:
- 들어오는 사람이 b나라면 쫓아내는거 +들어오는 사람이 총을 들고오면 총은 뺏고 들여보내주는거
- 리스너 :
- 여기 살고잇는 높은 사람이 술친구가 필요한 거임
- 양반 : 문지기야, 술 잘먹는 사람 좀 찾아내라
- 문지기 : 필터로 거르는 것도 바빠죽겟는데….;;; 다른사람시키세요
- 양반 : 그럼 사람(=리스너) 하나 더 뽑아서 술잘먹는사람 찾아야징ㅋㅋ
- 그럼 문지기가 필터를 통해 일 하고 있는 동안 리스너가 같이 들어오는 데이터들을 지켜본다.
- 리스너가 옆에 서서 술 잘먹는사람 찾으면 더 이상 다른 필터 검사 거칠 필요 없이 (web.xml의 일반적인 나머지 처리 절차가 남아 있다고 해도)바로 그 사람을 뽑아서 안에 들여감.
- 보안
- 이상한사람 쫓아보내는거, 현상수배범이 들어오면 감옥으로 보내는거,,
이런 기능들이 있어서
웹에 진입하면 최초에 도는게 바로 web.xml
⇒ 얘가 할일이 너무 많기 때문에
frontController 패턴을 쓴다.
여기에서 Servlet/JSP 매핑시(web.xml에 직접 매핑 or **@WebServlet 어노테이션 사용)**에 모든 클래스에 매핑을 적용시키기에는 코드가 너무 복잡해지기 때문에 FrontController 패턴을 이용함.
참고 : https://galid1.tistory.com/487
Servlet - Servlet 개념
Servlet이란 Servlet이란orcle 문서 : https://javaee.github.io/servlet-spec/downloads/servlet-3.1/Final/servlet-3_1-final.pdf - Java의 CGI 프로그램(WebServer와 WAS가 소통하기위해 CGI의 규칙을 준수한) 즉, 클라이언트 요청에
galid1.tistory.com
(4) FrontController 패턴
최초 앞단에서 request 요청을 받아서 필요한 클래스에 넘겨준다. 왜? web.xml에 다 정의하기가 너무 힘듬.(Servlet/JSP 매핑 데이터가 많아질 수록)

요청이 톰캣으로 가면
request 객체 (요청한 사람의 정보 : 어떤데이터를 내게 요청했는지, 어떤 데이터를 들고왔는지)
reponse객체는 내가 줘야할 것(request를 토대로 한)
이 두 객체를 톰캣이 자동으로 만들어줌
객체이므로 request. 으로 함수 사용 가능!

web.xml 에 jsp servlet 매핑이 너무 많으면 일하기 힘들기때문에,
특정주소(ex .do라는 주소)는 frontController가 낚아챔
원래는 request로 내부자원에 접근 못하게하지만 이미 이 자원은 frontController를 통해서 집 안에 들어온 상태(내부) 이기때문에 접근 가능!
근데 이렇게되면 처음 들어왔던, 최초의 request와는 다른 new 요청이 되는거다.
리퀘스트와 리스폰스는 할때마다 새로운 요청이 되므로 전에 있던 frontController가 낚아 채기 전 최초의 리스폰스에 남아있던 request에 담긴 A에 대한 정보가 사라진다.
그래서 아래의 RequestDispatcher가 필요하다.
(5) RequestDispatcher
필요한 클래스 요청이 도달했을 때 FrontController에 도착한 request와 response를 그대로 유지시켜준다.

새 요청이 들어오면 또 새로운 request, response가 생기며 전의 요청이 사라지기 때문에(거기에 담았던 a라는 데이터까지)
전의 요청을 그대로 유지해야한다. 뭘위해서? a라는 페이지에서 데이터를 들고 b라는 페이지로 이동하기 위해서.
즉 데이터를 들고 페이지를 이동하기 위해 RequestDispatcher 가 필요하다.
(6) DispatcherServlet = FrontController + RequestDispatcher
FrontController 패턴을 직접짜거나 RequestDispatcher를 직접구현할 필요가 없다. 왜냐하면 스프링에는 DispatcherServlet이 있기 때문이다. DispatcherServlet은 FrontController 패턴 + RequestDispatcher이다.
DispatcherServlet이 자동생성되어 질 때 수 많은 객체가 생성(IoC)된다. 보통 필터들이다. 해당 필터들은 내가 직접 등록할 수 도 있고 기본적으로 필요한 필터들은 자동 등록 되어진다.
(7) 스프링 컨테이너
스프링은 아파치가 발동할 수가 없음. 정적 파일을 안주니까 ( url 이 아닌 uri로 ) 머리에서 지우셈
스프링은 전부 자바파일(서블릿)을 요청함.

그래서 어떻게 작동이 되느냐.,.
request⇒ web.xml⇒ DispatcherServlet 동작 (front+reqdispather)
DispatcherServlet 의 궁극적 목적 = 주소 분배 + 메모리 띄우기(왜?)== 컴포넌트 스캔
왜?
주소를 분배하려면 그 주소로 갔을때 class들이 메모리에 떠있어야 하므로
주소로 찾아갔는데 아무것도 없다면?? 분배하는 의미가 없으니까!
static : main 메소드 ⇒ 계속 살아있는애들
자바파일은 객체 : 특정한 시간에 살아있다가 죽는 애들
그런데 여기서 이 객체를 내가 하나하나 다 new 어쩌구로 띄우냐? 아니다
스프링은 IoC기법을 쓰니 스프링이 자동으로 객체를 관리해줌.
스프링 부트부터는 컴포넌트 스캔을 할 때 작업 패키지 이하 모든 파일을 스캔함.
Q. 그런데 전부 다 스캔해버리면 뭐가 필요하고 뭐가 필요없는앤지 어떻게 압니까? 필요없는애도 있을거아뇨??
⇒ 그래서 필요한게 스프링의 다양한 어노테이션

저 빨간것들은 스프링이 정해놓은것. 스프링은 스캔할때 저 어노테이션을 보고 필요한 것들을 객체에 띄움
어노테이션은 만들수도 있지만 초보자가 만들일은 잘 없음..있는거나 잘쓰자!
DispatcherServlet에 의해 생성되어지는 수 많은 객체들은 ApplicationContext에서 관리된다. 이것을 IoC라고 한다.
첫째,ApplicationContext
IoC란 제어의 역전을 의미한다. 개발자가 직접 new를 통해 객체를 생성하게 된다면 해당 객체를 가르키는 레퍼런스 변수를 관리하기 어렵다. 그래서 스프링이 직접 해당 객체를 관리한다. 이때 우리는 주소를 몰라도 된다. 왜냐하면 필요할 때 DI하면 되기 때문이다.
DI를 의존성 주입이라고 한다. 필요한 곳에서 ApplicationContext에 접근하여 필요한 객체를 가져올 수 있다. ApplicationContext는 싱글톤으로 관리되기 때문에 어디에서 접근하든 동일한 객체라는 것을 보장해준다.
ApplicationContext의 종류에는 두가지가 있는데 (root-applicationContext와 servlet-applicationContext) 이다.

서블릿이 만들어지면 스레드가 만들어진다.
요청한 사람 100명 , 스레드 20일때 요청이 들어올 때 마다 새로운 객체가 계속 만들어져서 각각 다른 객체가 됨.

컴포넌트스캔을 하면 스레드별로 다 따로 객체를 띄워주는거지만 스레드가 공통으로 써야하는 것도 있음.
⇒ 그건 바로 데이터베이스 커넥션(DB)

그래서 바로 DispacherServlet에 가기 전, ContextLoaderListener 가 스레드가 공통으로 써야하는 애들을 찾음.
ContextLoaderListener 가 root-applicationContext.xml(자바파일일수도) 파일을 읽으면
- root-applicationContext : 스레드별로 공통으로 써야할 애들이 적혀있음
그런데 여기서 ContextLoaderListener 이 먼저 실행 된 후 DispacherServlet가 실행되니깐,
ContextLoaderListener d에 있는 db에서 DispacherServlet에 의해 뒤에 만들어지는 클래스들에 접근이 불가능!
servlet-applicationContext에서는 root-applicationContext가 로드한 객체를 참조할 수 있으므로 클래스들은 db가 필요할 때마다 root-applicationContext가 로드한 객체를 참조 한다.
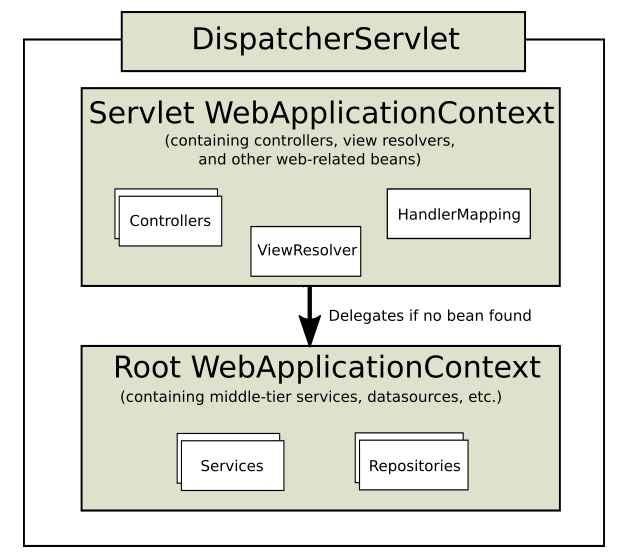
a. servlet-applicationContext
servlet-applicationContext는 ViewResolver, Interceptor, MultipartResolver 객체를 생성하고 웹과 관련된 어노테이션 Controller, RestController를 스캔 한다.
============> 해당 파일은 DispatcherServlet에 의해 실행된다.
얘는 즉, 웹과 관련된 어노테이션만 스캔하는애.
b. root-applicationContext
root-applicationContext는 해당 어노테이션을 제외한 어노테이션 Service, Repository등을 스캔하고 DB관련 객체를 생성한다. (스캔이란 : 메모리에 로딩한다는 뜻)
============> 해당 파일은 ContextLoaderListener에 의해 실행된다.
ContextLoaderListener를 실행해주는 녀석은 web.xml이기 때문에 root-applicationContext는 servlet-applicationContext보다 먼저 로드 된다.
당연히 servlet-applicationContext에서는 root-applicationContext가 로드한 객체를 참조할 수 있지만 그 반대는 불가능하다. 생성 시점이 다르기 때문이다.

https://blog.kakaocdn.net/dn/q43e6/btqCvx1OYiy/MJv6bpvTjEtC4XsNsR4m71/img.png
출처 : https://minwan1.github.io/2018/11/21/2018-11-21-jsp-springboot-동작과정/
둘째, Bean Factory

어떤 @Configuration를 붙이면 스캔이된다.
저 클래스의 메소드가 리턴하는 객체가 있다면
그 객체를 @Bean 을 통해서 메모리에 띄울 수 있다.
필요한 객체를 Bean Factory에 등록할 수 도 있다. 여기에 등록하면 초기에 메모리에 로드되지 않고 필요할 때 getBean()이라는 메소드를 통하여 호출하여 메모리에 로드할 수 있다.
이것 또한 IoC이다.
그리고 필요할 때 DI하여 사용할 수 있다.
ApplicationContext와 다른 점은 Bean Factory에 로드되는 객체들은 미리 로드되지 않고 필요할 때 호출하여 로드하기 때문에 lazy-loading이 된다는 점이다.
(8) 요청 주소에 따른 적절한 컨트롤로 요청 (Handler Mapping)
GET요청 => http://localhost:8080/post/1
해당 주소 요청이 오면 적절한 컨트롤러의 함수를 찾아서 실행한다.
참고: https://minwan1.github.io/2017/10/08/2017-10-08-Spring-Container,Servlet-Container/
(9) 응답
html파일을 응답할지 Data를 응답할지 결정해야 하는데 html 파일을 응답하게 되면 ViewResolver가 관여하게 된다.

ViewResolver가 뭔데?
-html파일을 응답(jsp로 받아서 다시 톰캣이 html로 응답하니께!)
- 요청 주소가 들어오면,
- DispatcherServlet이 바로 주소요청을 처리하는것이 아니라, Handler Mapping 이 대신 요청주소에 맞는 컨트롤러의 함수를 찾아 실행한다.
- 이때 ViewResolver가 "hello" 앞 뒤에, web-inf /views/hello.jsp 를 prefix로 붙여줌
- prefix값에 맞는 주소 파일을 찾아감
-Data를 응답
반대로,

그냥 특정 파일이 아닌 메시지 주고싶다면 @ResponseBody를 붙여주면 됨 (=>data 응답)

하지만 객체를 응답하게 되면 MessageConverter가 작동하게 되는데 메시지를 컨버팅할 때 기본전략은 json이다.

여기서 잠깐! MessageConverter 로 한번 거치고 가는 이유
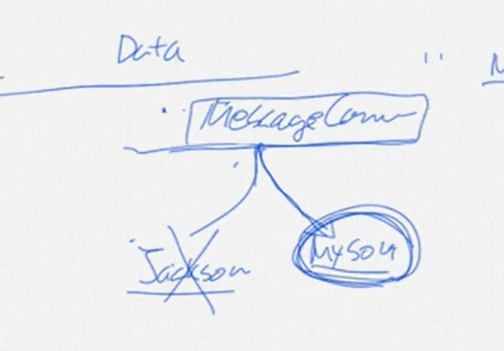
나중에 Jackson보다 더 나은 무언가 (예를들어 Myson) 이라는게 생긴다면,
json을 쓴 파일들을 전부 교체해줘야함
근데 MessageConverter 를 만들어 추상객체에 바인딩하는 방식을 쓴다면 추후 어떤 것이 나와도 코드 유지보수가 쉬움
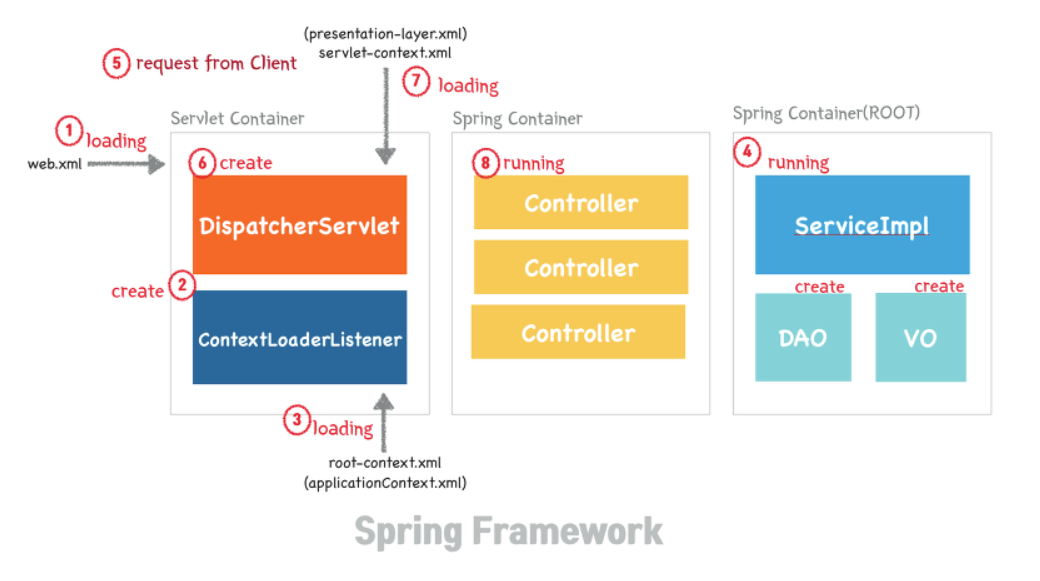
!https://blog.kakaocdn.net/dn/qntbk/btqCzBhZ33L/ifWzqKL76nFdalVNzKApk1/img.png

최종 :
- loading (톰캣 실행시(request요청 왔을때가 아님!@!!)) :되면서 문지기가 설정파일을 쫙 읽음
- create: ContextLoaderListener가 create되면서
- applicationContext가 읽어지면서 root-context 가 읽어짐(db관련 )
- root-context로 읽은 DB관련 정보를 ServiceImpl, Dao, VO 로 메모리에 띄움
- 그다음에 사용자에게 request 요청이 들어옴.
- servlet -context.xml 가 DispatcherServlet에 의해서 웹과 관련된 아이들을
- 메모리에 띄우면서
- 각각 맞는 주소에 배정해줌
- 이제 이걸 Data로 리턴할지 html파일로 리턴할지 결정해서 리턴하면 끝!
자료 출처 : 스프링부트 강좌 with JPA -메타코딩
'백 > spring boot' 카테고리의 다른 글
| 스프링부트 - mybatis 사용하기 (0) | 2023.07.12 |
|---|---|
| 스프링 부트 프로젝트 생성하기(gradle) (0) | 2023.07.12 |
| 스프링 부트 프로젝트 생성하기(Maven) (0) | 2023.07.12 |
| 스프링 부트 2. JPA (0) | 2023.06.19 |
| 스프링부트 1. 기본개념정리 (0) | 2023.06.19 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}